劔"Tsurugi"は、新しいハードウェアのアーキテクチャに合うRDBMSとして開発を行っています。
CPUは微細化が限界に達し、メニーコア化を進めており、一方で、メモリーデバイスも高機能(不揮発性メモリーの登場)・高密度化(メモリー容量の伸張)が進んでいます。
既存のRDBMSは、"コア数が少ない"、"メモリー容量は制限的である"という前提で作られており、基本的なアーキテクチャの思想としては永らく変わっておらず、新しいハードウェアアーキテクチャ(メニーコア・大容量メモリー)で性能を発揮しづらくなっています。
劔"Tsurugi"は、新しいハードウェアアーキテクチャに合わせた設計思想に基づいて開発され、その上で性能を最大限に発揮するデータベースです。
劔"Tsurugi"の特徴

超高速バッチ処理が可能
他のRDBと異なり、書き込み性能が強く、バッチ処理が高速です。また書き込み・読み込みともにロックフリーであるため、バッチ処理とオンライン処理を併用できます。
従来のdiskベースのRDBは書き込み性能が遅く、結果として、特に大量のデータを書き込む、または大量のデータを一気に読み込みかつ書き換える処理に極めて低速です。いわゆるバッチ処理に時間がかかってしまいます。また、大量のデータの書き込みは、データの整合性を保つためには大量のロック処理を要求します。これはデータベースの大きなパフォーマンス劣化を引き起こします。
劔"Tsurugi"はすべてのデータ処理をメモリー上で実行するインメモリー処理を実行基盤とし、データの整合性を保つためにロック処理を利用しない、ロックフリーの仕組みを導入しています。このため、バッチ処理自体が極めて高速に完了させることができます。またロックフリーにより、バッチ処理の最中に、バッチ処理の対象のデータにリード・ライトともにアクセスすることができるため、バッチ処理とオンライン処理の併用が可能になっています。
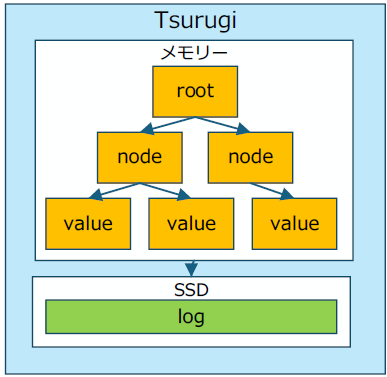
・インメモリー処理
劔"Tsurugi"では処理すべきデータはすべてメモリー上に持ちます。Disk等の永続化層はデータの保全のためだけに利用します。このため従来のRDBのように必要な時にデータを永続化層からロードするコストがかかりません。永続化層への書き込み・読み込みを最小限にしているため、キャッシュ汚染を押さえることに成功しており、全般的な高速処理を提供しています。
永続化への書き込み処理はすべてグループコミットとなっており、可能な限りの高い書き込みのパフォーマンスを提供しています。
・ロックフリー
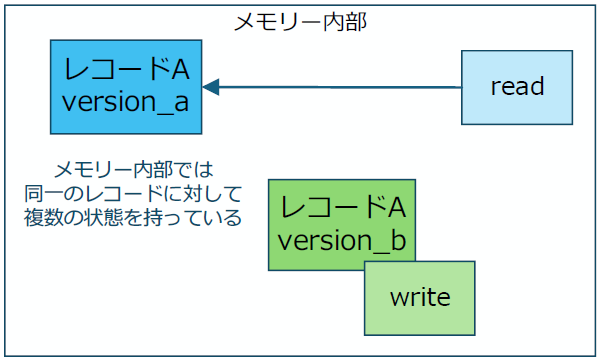
従来のRDBでは一貫性の担保のために、ロック機構を利用して、特に書き込み処理中に対象のレコードにロックをとっていました。これに対して劔"Tsurugi"は現代的なMVCC(Multi-Version Concurrency Control)ですべての処理を行っており、一貫性担保のためのロックは一切とっていません。
複数の状態(version)を許すため、すべての値について物理コア数分の状態を持つことが可能となっています。
複数状態の同時書き込みと、確定状態に対する読み込みを同時並行的に実行可能です。
物理順序とは別に一貫性担保を論理順序で管理しているため、可能な限りの広い論理空間でのコミットが可能となっており、オンライン処理同士はもちろん、オンライン/バッチ処理間でも整合を保って同時に処理することが可能になっています。
低遅延のAI実行環境を実現
インメモリー処理を活かして、きわめて低遅延でAI処理を実行することが可能です。
ロックフリーであるので、データの書き込みをしながら、同時にそのデータに対して低遅延で推論を実行することが可能です。
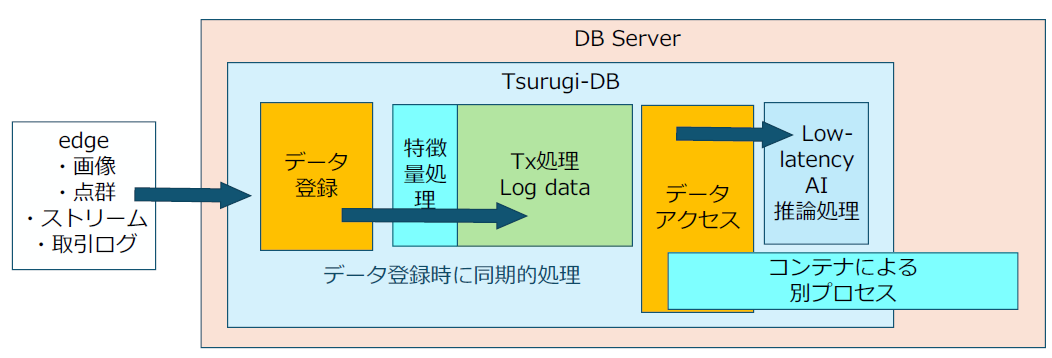
IoT系やOT系では、機器・装置・センサーから大量のログデータ・観測データが生成されます。このログストリームは今までのRDBでは性能不足のため書き込みができませんでした。また、仮にそれ以外の手法でデータを取得することができても、整合性をもってかつリアルタイムで処理することが非常に困難でした。このため、いままでは、このログストリームの処理は、機器・装置・センサーの端末等のエッジサイドで実行する必要があり、専用チップや組み込み系の仕組みで実行されていました。
このような専用の仕組みは、納期やコストが嵩み、また機能制約が強い上に、試行錯誤が制限的にならざるを得ません。特にAIのような日進月歩のテクノロジーの採用には極めて不利になります。
劔"Tsurugi"では、このような低遅延の大量のログストリームについて、組み込みや専用チップのような特別な仕組みによらず、そのままオープン系の仕組みでAI系の処理を実行することができます。
・大量ログストリームの低遅延での書き込み
インメモリー処理である劔"Tsurugi"では、投入されるログストリームやトランザクションデータについて、高速でデータクレンジングを実行しつつ、整合性をとって書き込むことが可能です。データクレンジングは、通常の結合処理を行うことで実行可能であり、結合処理を行いながら数ミリ秒以下で書き込みを実行します。
この結合処理は、特段の特殊な処理体系ではなく、一般的なSQLで記述できます。劔"Tsurugi"がロックフリーの機構であるため、書き込みが待たされることなく、低遅延のまま、高いスループットを維持できます。
・同時にAI処理を非同期・同期で実行することが可能
劔"Tsurugi"がロックフリーであることを利用して、ログストリームやトランザクションデータを書き込みつつ、非同期でリアルタイムに書き込まれたデータに対して、AI処理を実行することが可能です。AI処理として学習済みモデルをデータに適用し、10ミリ秒~50ミリ秒で推論を実行することが可能です。
この低遅延のアーキテクチャにより、画像解析からの物体検出等の処理をミリ秒のオーダーで実行することができます。また、画像データや推論結果はそのままTsurugiに格納されるため、同時にSQLに検索を実行することも可能です。
・独立した推論モジュールの実装
推論モジュールはコンテナベースでデプロイすることも可能で、パフォーマンスはnative実行に比較して3%程度の劣化に押さえられます。コンテナベースにすることで環境依存性を分離することが可能になるため、推論プログラムの実行環境を自由に選択・調整・変更することができます。
これにより試行錯誤性が非常に高く、コスト・納期・機能制約についてすべての面でメリットが取れるソリューションを実行することができます。
ローカルLLMとMCPをサポート
MCPによりAIを利用して自然言語で劔"Tsurugi"を操作することが可能です。
ローカルLLMを利用して、インターネットと独立のスタンドアローンの環境で運用ができます。
ほとんどの企業内部の業務系のデータはデータベースで管理されています。業務上のアプリケーションの利活用のサポートをAIに行わせるのであれば、AIによるデータベースへのアクセスは必須と言えます。
このときに、クラウド上のAI(LLM)を利用する場合、データベースへのアクセスをクラウドAIにオープンにする必要があり、セキュリティ上の懸念が発生します。
また、AIのハルシネーションの発生リスク等、実行結果を担保することが困難です。加えて、トークンベースのAIの利用料金が予想困難という課題もあります。
・適切なアーキテキチャの提供
劔"Tsurugi"ではMCPサーバのインターフェースを提供しています。
MCPサーバに加えてローカルLLMを利用することで、データベース(劔"Tsurugi")+MCPを中心に据えるAIシステムをクローズドに構築することができます。ユーザの手元に明確なシステム・アーキテクチャを構成することで、AI(LLM)の位置づけをはっきりさせ、業務系AIシステムの品質・コスト・運用の見通しを明確にすることができます。
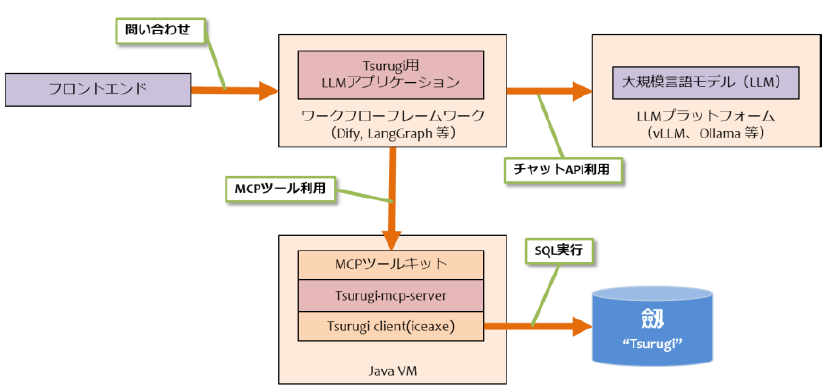
・MCPインターフェース
データベース+MCPのアーキテクチャはLLMに「縛りをかける」ことが可能になるため、実行正確性が担保されます。また、同時にローカルLLMを利用することで、さまざまなメリットを享受することが可能になります。
・品質・パフォーマンス測定
MCPによりLLMのアウトプットを制約できるため、そのLLMの精度を定量化することが可能です。またLLMの遅延・スループットを計測することができるため、さまざまなLLMを実際に実行して、そのパフォーマンスを正確に評価し、比較することが可能です。また、実運用中のLLMのパフォーマンス品質を自社のコントロール下で維持することも可能になります。
・セキュリティ
AIアーキテクチャの環境をスタンドアローンで実行・運用することが可能です。これによりローカルLLMが外部と通信することを物理的に完全に遮断できるため、企業内の機密情報にAIをアクセスさせても漏えいのリスクがありません。
・コスト低減
ローカルLLMの実行はクラウドLLMの実行と異なり、トークン課金が発生しません。
AIの導入・運用コストを予算範囲内で制限なしで実現することが可能です。
さまざまなインターフェースを利用可能
JavaAPI・WebAPI・ODBC・JDBC等の様々なAPI・ライブラリーをサポートしています。クライアント・アプリケーションは特定の環境に依存しません。Rust FFIも提供しているため、自由に拡張することができます。
現在の企業活動でデータベースの利用は欠かすことができません。
そのニーズや用途、利用シーンの多様化から、データベースのアクセス方法・利用方法にも様々な手法が要求されています。フロントエンドは勿論、バックエンドの拡張も必要とされます。従来のRDBのようなモノリシックな構造では、拡張の度に影響するコードすべてに広く手をいれていくことになり、コードベースの肥大化・パフォーマンス/品質の劣化・リリースの遅延につながることになります。
劔"Tsurugi"では、広い拡張性を担保するために、コンポネントベースでのアーキテクチャを採用し、インターフェースの拡張・変更等が局所化されるように設計・実装されています。これにより、コードベースの肥大化を防ぐと同時に、パフォーマンスの劣化を抑え込んでいます。
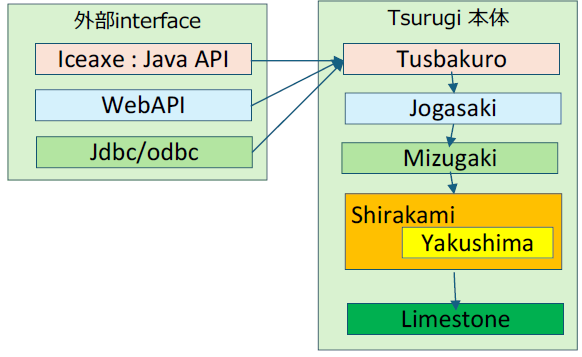
・フロントエンドで提供されるインターフェース
| コンソール | 劔"Tsurugi"に直接SQLを発行するCLIツール |
| クライアントAPI(Iceaxe) | JavaでSQLを実行するための外部インターフェースで、細かな制御をアプリケーションより実行するためのAPIライブラリーです。 |
| JDBC | Javaから劔"Tsurugi"にアクセスしてSQLを実行するためのドライバーになります。 |
| ODBC |
Microsoftの製品群から劔"Tsurugi"にアクセスしてSQLを実行するためのドライバーになります。 |
| Web API |
特定のアプリケーションを介さずにREST APIで劔"Tsurugi"にアクセスするためのAPIです。Dump/Loadを実行することが可能です。 |
| UDF | 劔"Tsurugi"内部から外部の関数呼び出す機構 gRPCのクライアント・ライブラリーが組み込まれており、SQLに外部で定義した処理を組み込むことが可能です。) |
・拡張用Rustインターフェース
RustのFFI(Foreign Function Interface)を用いたC言語ラッパーです 。
C言語上のプログラムから劔"Tsurugi"に対する操作を実行することが可能となります。このFFIを利用することで、他の言語からの利用APIを実装することができます。
・バックエンドの拡張性
劔"Tsurugi"のコンポネントベースの拡張性はバックエンドにまで及んでいます。
通常のRDBであればモノリシックになっている並行性制御モジュールとloggerが分離して実装されています。Loggingを司るライブラリーがWALの管理を並行性制御から独立して行っているため、WALを直接拡張することが可能です。
この拡張性により、Tsurugiでは並行性制御に依存せずに、レプリケーションの実装を提供することに成功しています。
サポート・サービスについて
劔"Tsurugi"のサポート・サービスは、劔"Tsurugi"をご利用頂いている方からの問い合わせを、
個別の問い合わせ窓口を設けて受け付けるものです。
劔"Tsurugi"を活用してシステムの構築・運用をする方に対して、設計フェーズからの問い合わせを受け付けます。
詳しくは、本サイトの"サポート"をご覧ください。
ダウンロードについて
劔"Tsurugi"は現在、オープンソースにて公開中です。
GitHubよりダウンロードいただきご使用ください。
> 劔"Tsurugi" GitHub ページ
また、劔"Tsurugi"について解説した書籍も現在発売中です。
是非、ご参考ください。
お問い合わせ
劔"Tsurugi"に関する問い合わせや、劔を利用したPoCや共同実証を行いたいなどのご相談は、
下記のフォームからお問い合わせください。
> 劔"Tsurugi" お問い合わせフォーム
また、商用サポートのお問い合わせも、上記のフォームより受け付けております。
是非ご活用ください。